Project Overview
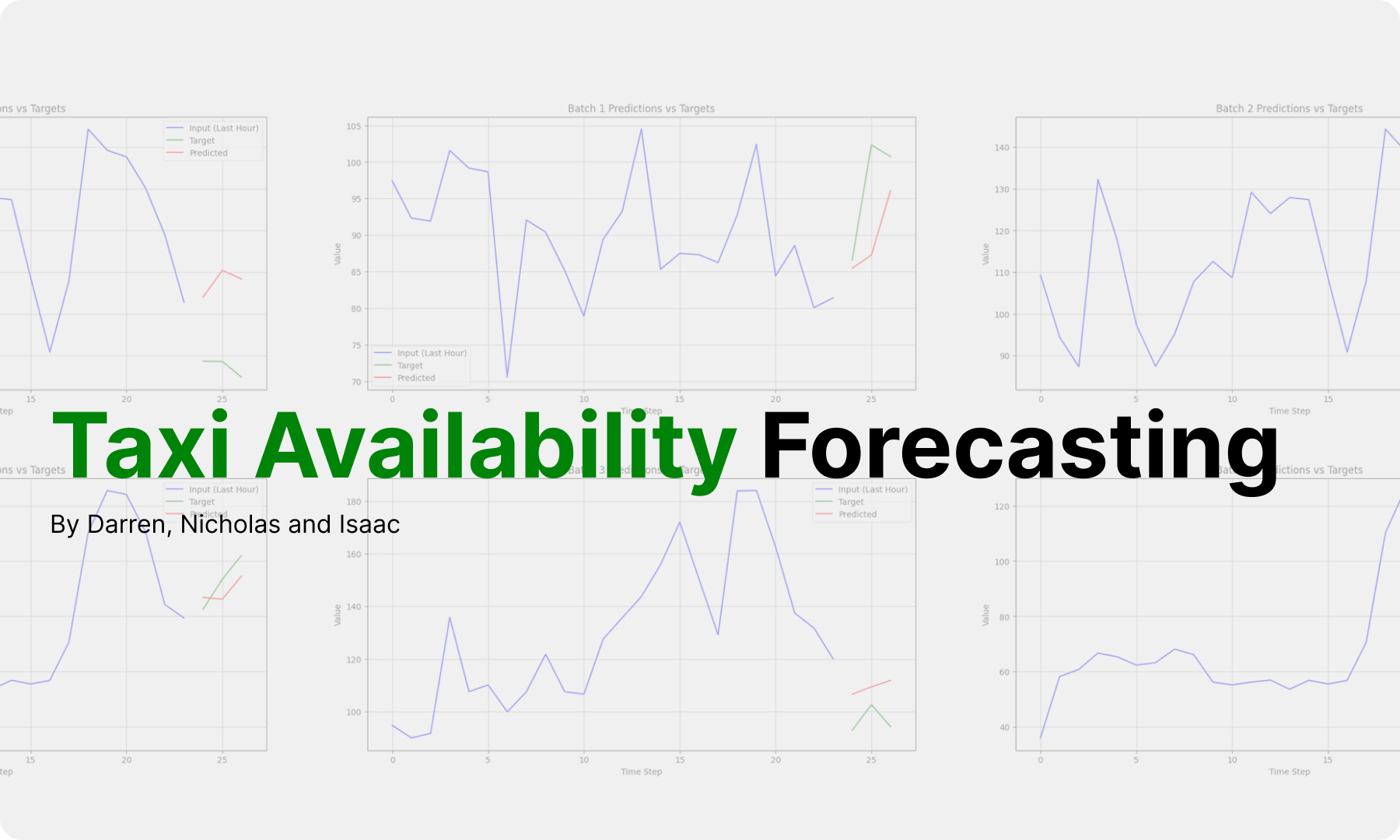
With my teammates, we experimented with several deep learning models to see how well they can predict taxi availability.
Overall, we experimented with the following models:
- Long Term Short Term Memory (LSTM)
- Bidirectional LSTM
- Encoder-Decoder LSTM
- Bidirectional Encoder-Decoder LSTM
- Transformer
- XGBoost + Random Forest (Referencing this paper)
Problem Scope
The goal is to predict taxi availability in a given area for the next 3 hours, leveraging the consistent trends in taxi deployment. This can help passengers identify optimal times to book a taxi with minimal wait and assist taxi companies in optimizing fleet deployment by reducing excess supply during periods of high availability.
Implementations
Data Gathering
As with most machine learning project, the first step and most important step is to gather data.
The first data we needed was taxi availability data. To curate this dataset, we called the Taxi Availability Dataset from data.gov.sg at 5 minutes intervals for 3 years.
We then filtered the data to only include the area around the school as that is what we were interested in.
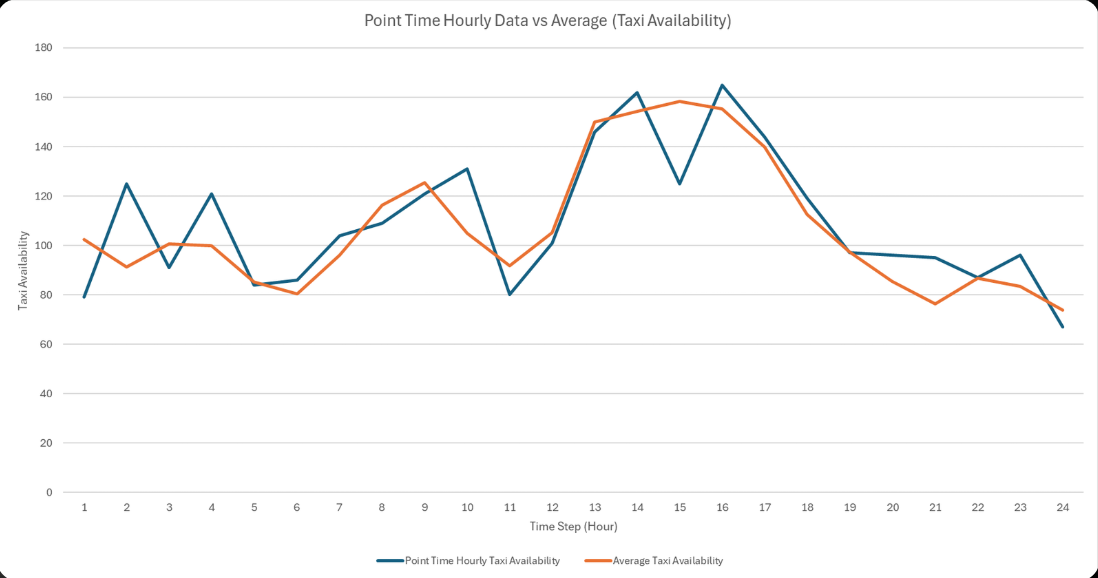
To reduce noise and highlight overall trends, we averaged the data from 5-minute intervals into hourly intervals. Simply using point hourly data can introduce unwanted spikes and dips, but aggregating the 5-minute data helps smooth out these fluctuations for a clearer view of availability patterns as shown below.
We also gathered weather data from the weathers API as well
as a isPeakHour and isWeekend boolean to serve as additional features to our model.
Lastly, we cleaned the data and created our sequence by slicing the data into 24 hour non-overlapping sequences. Our rationale for doing so can be found in our report.
Training, Hyperparameter tuning and evaluation of models
We then coded our models in Python with the help of PyTorch, trained them and finally evaluated them using loss as well as Mean Absolute Error.
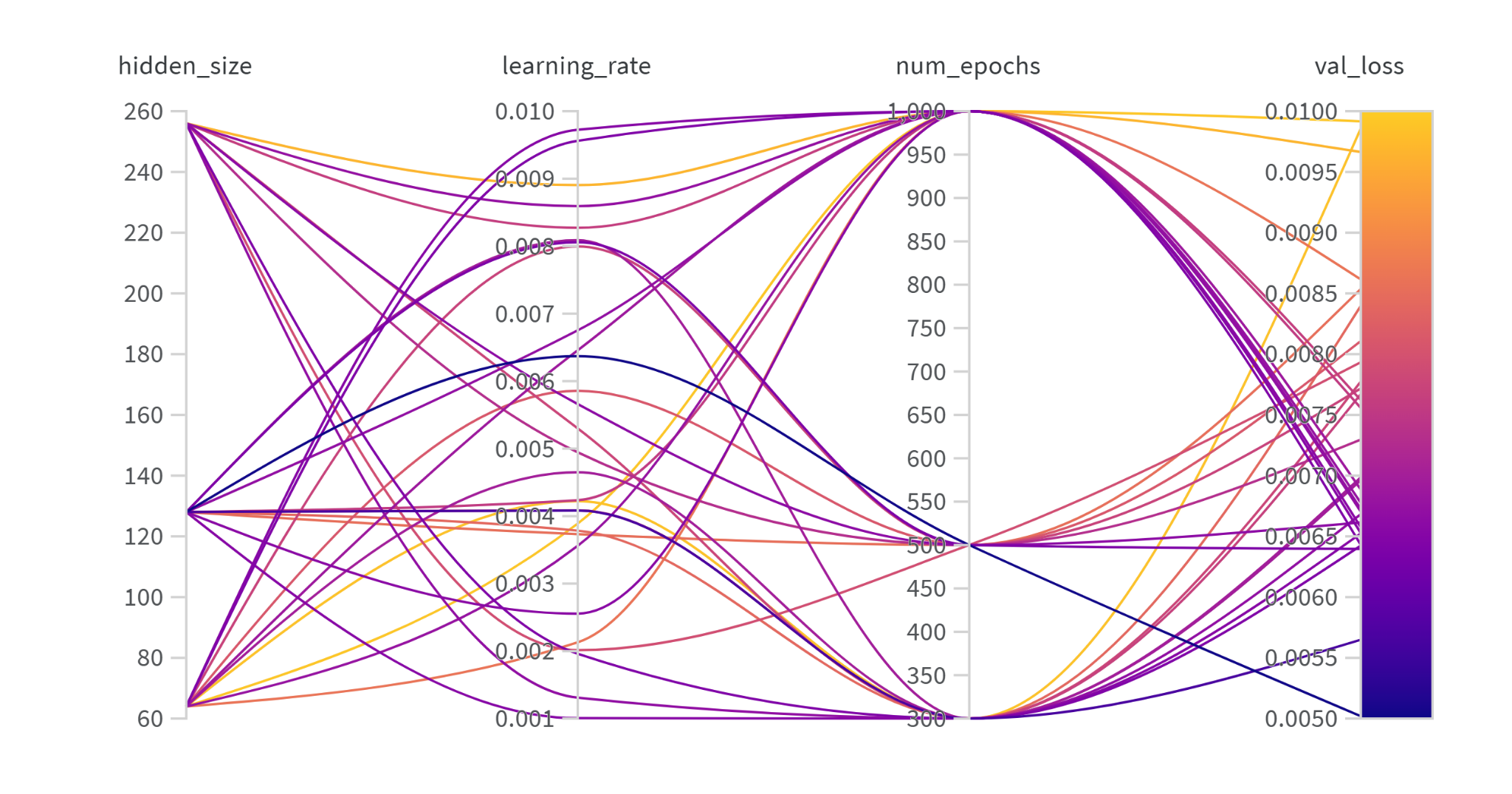
We also did hyperparameter tuning using Bayesian Search and recorded our results using
Weights & Biases.
We tuned for about 30 runs for each model and recorded the best hyperparameters for each model.
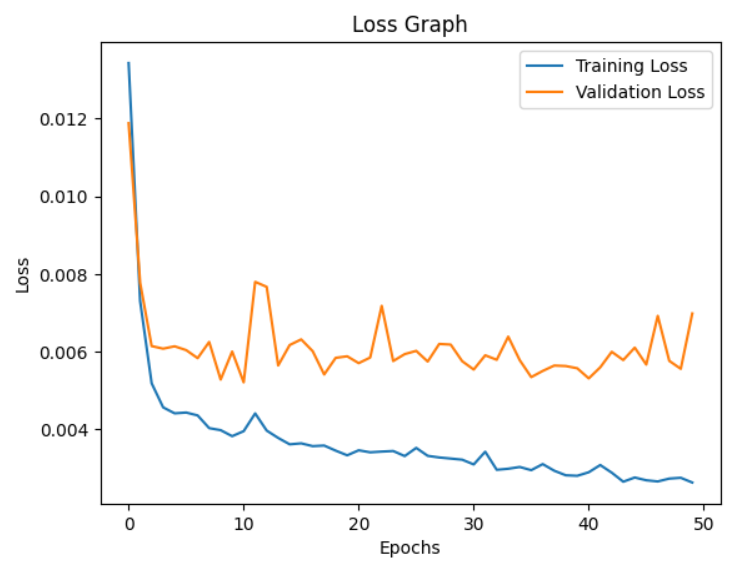
Below is an example of a training vs validation loss graph. This is for the base LSTM model. We can see that with LSTM models, there is a lot of overfitting even with hyperparameter tuning, dropout, early stopping and regularisation.
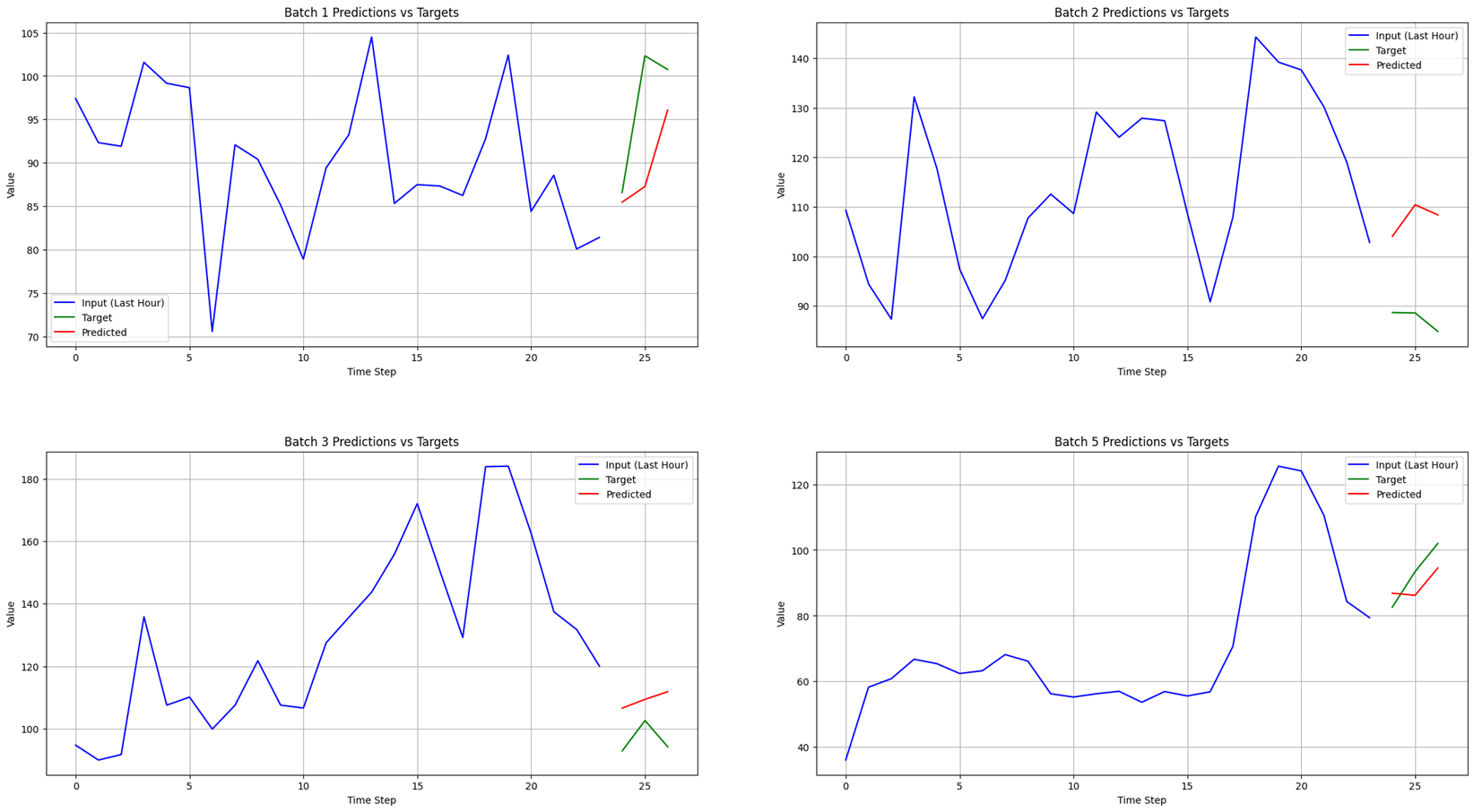
Finally below you can see how the model performed:
Final Comparison
After training and evaluating all 6 of our models, below were the results:
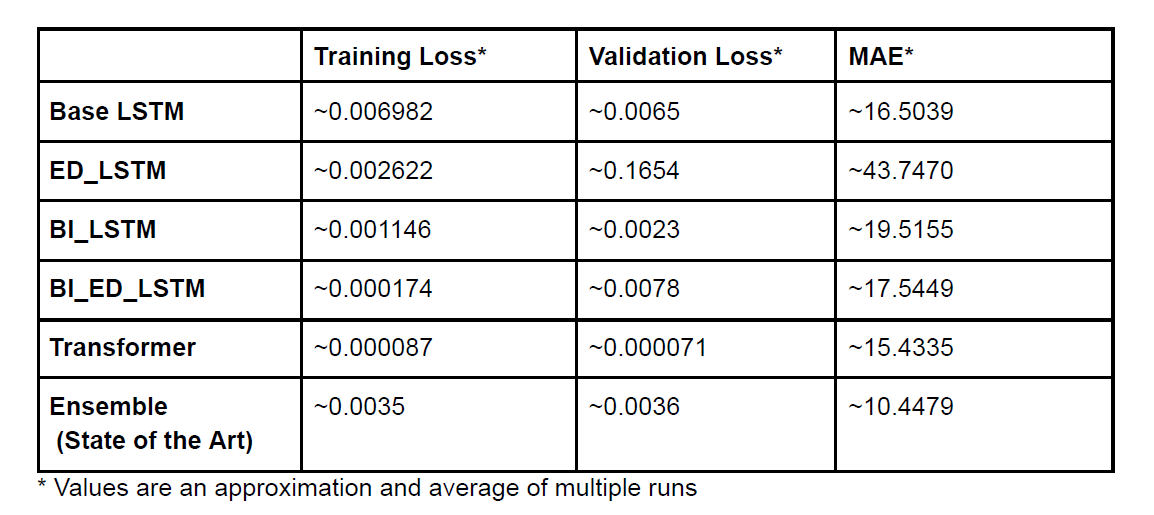
Transformers and Ensemble Models Perform Best
We can see that as “expected”, the Transformer and Ensemble models performed the best and were only on average
off by about 10-15 taxis. Considering that at any one time, the area will have 80-160 taxis, this is a pretty good result.
This can be best explained by the fact that the transformer having an attention mechanism will allow it to find
the most relevant data points in the sequence and learn the relationships between them. The ensemble model also perform well
because it uses decision trees which are good at capturing independent relationships between the features and the target variable.
LSTMs based models performed worse
We could see that the LSTM models were overfitting a lot. This likely meant that LSTM was too complex for the task. It likely
would have performed better if we chose to use a simpler model like Gated Recurrent Unit (GRU) instead.
Additionally, while LSTM is good at capturing temporal relationships, it might not have been able to
capture non-temporal ones like weather affecting taxi availability.
Improvements
A mistake that we made was that the area we chose encompassed Changi airport. This meant that the taxi availability
was likely affected by the arrivals and departures of flights which was not a feature that we used. But this also clearly shows that
different area will have different features affecting taxi availability so likely for this system to be used, there will need to be a
base model trained on just general features and each special zone will likely need to their own models that is finetuned on the base model.
Another issue was that the area size we chose was arbitrary and it might not have been ideal. We could have used a smaller area and
the model might have performed better. But if it is too small, then the data might also be too sparse. So there should be a balance here which
will need to be tuned using hyperparameter tuning.
Conclusion
Doing this project was a great learning experience for me. Not only was I able to build intuition on how different deep learning models would perform, I was also able to practice using tools like Weights & Biases.