Project Overview

As part of my coursework, my teammates and I built a QA finetuned RAG chatbot that answers questions about the Singapore University of Technology and Design (SUTD). Through this project, I learnt a lot about LLM behaviours, how they react to different embeddings, chunking, finetuning, prompts and much more.
Problem Definition
We set out with the objective to help prospective students get a better understanding of SUTD as information about the university can be hard to find and understand. We had hoped that this chatbot will be able to answer questions such as:
- What is the SUTD curriculum like?
- What are the different majors in SUTD?
- What are the admissions deadlines for SUTD?
Implementations
Web Scrapping
Before we start building the chatbot, we had to gather data and build up our knowledge base. We found out about the Zyte Web Crawler and used it to scrape the SUTD website.
I looked at the SUTD robot.txt and sitemap and decided to scrape all the pages with relevant paths such as /admissions, `/undergraduate’ etc.
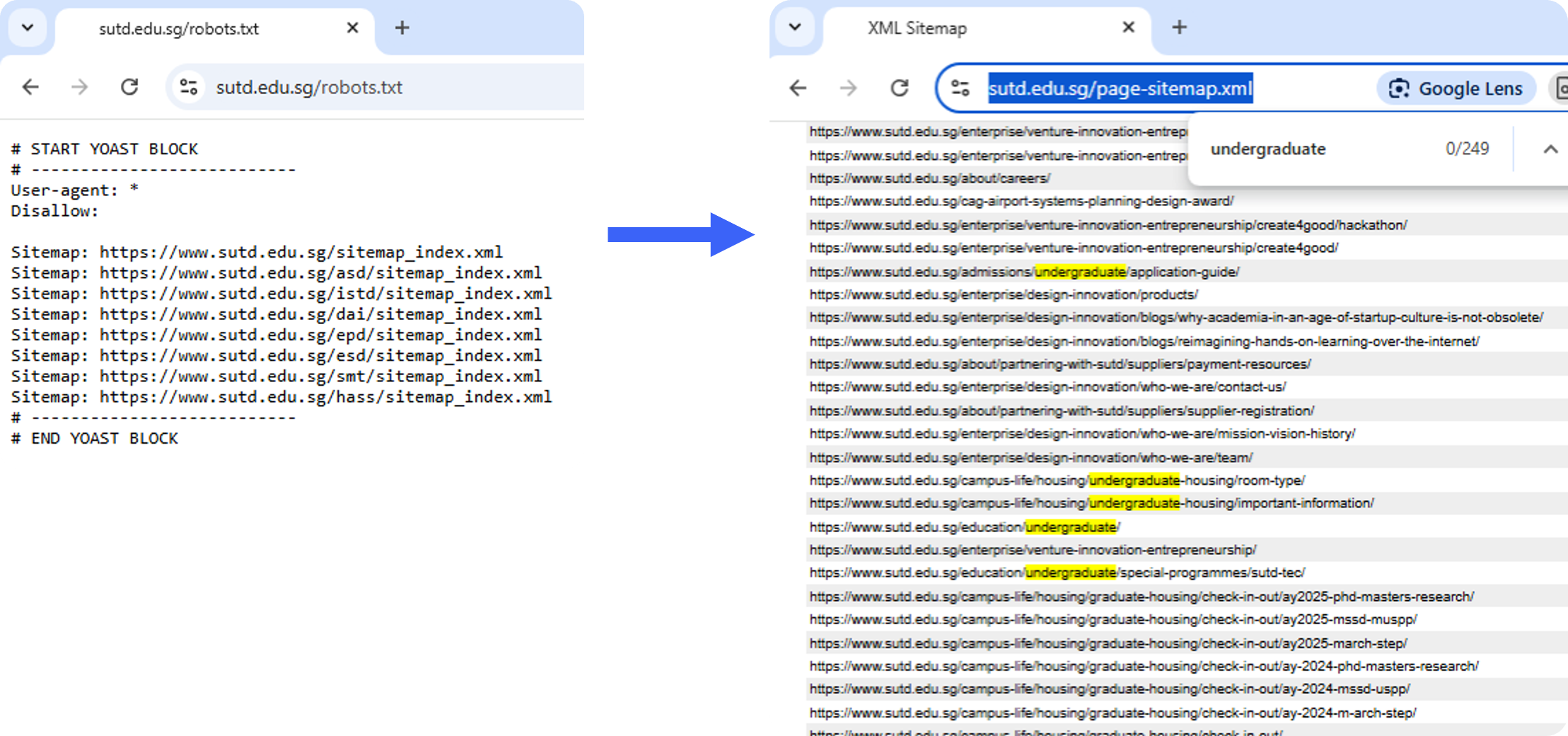
I then proceeded to scrap the websites and managed to retrieved more than 2,170 pages of data to build our knowledge base.
Chunking and Embeddings
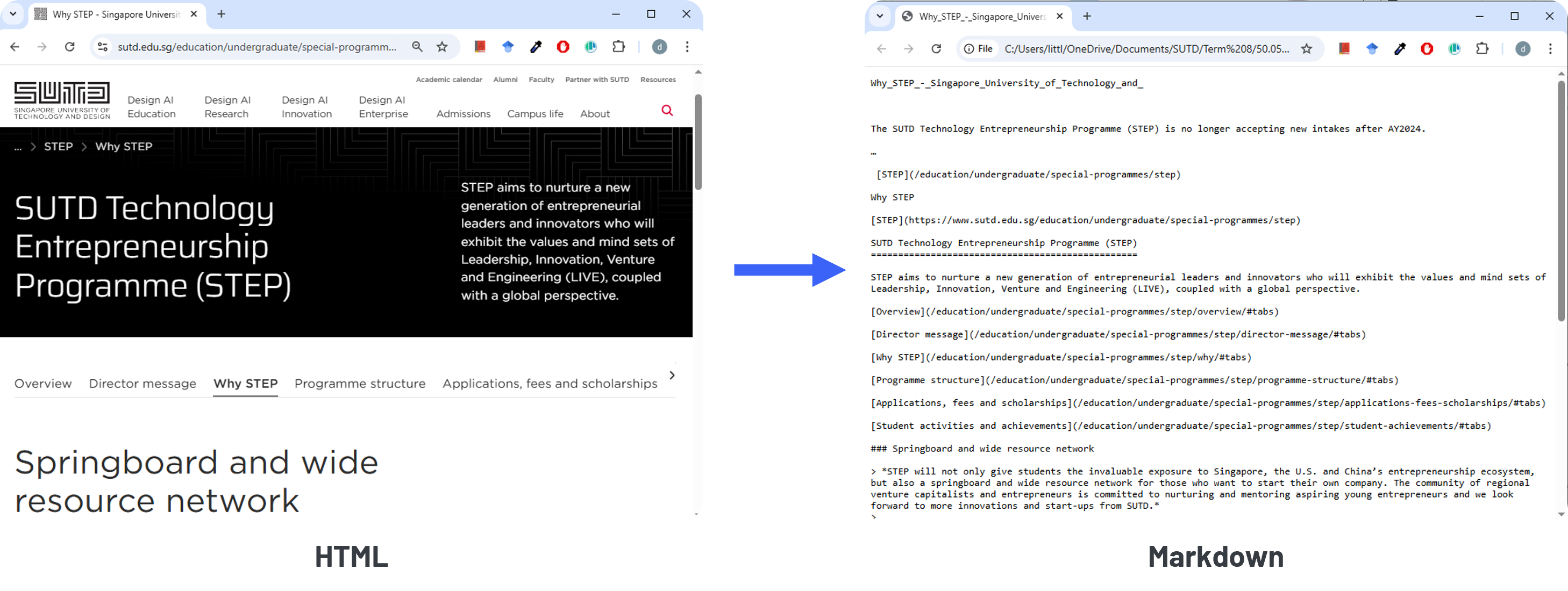
After scraping the data in HTML, we converted it to Markdown so that the text is easier to read with less noise. Additionally, we noticed that there are unnecessary information such as headers, footers and navigation bars so we removed those.
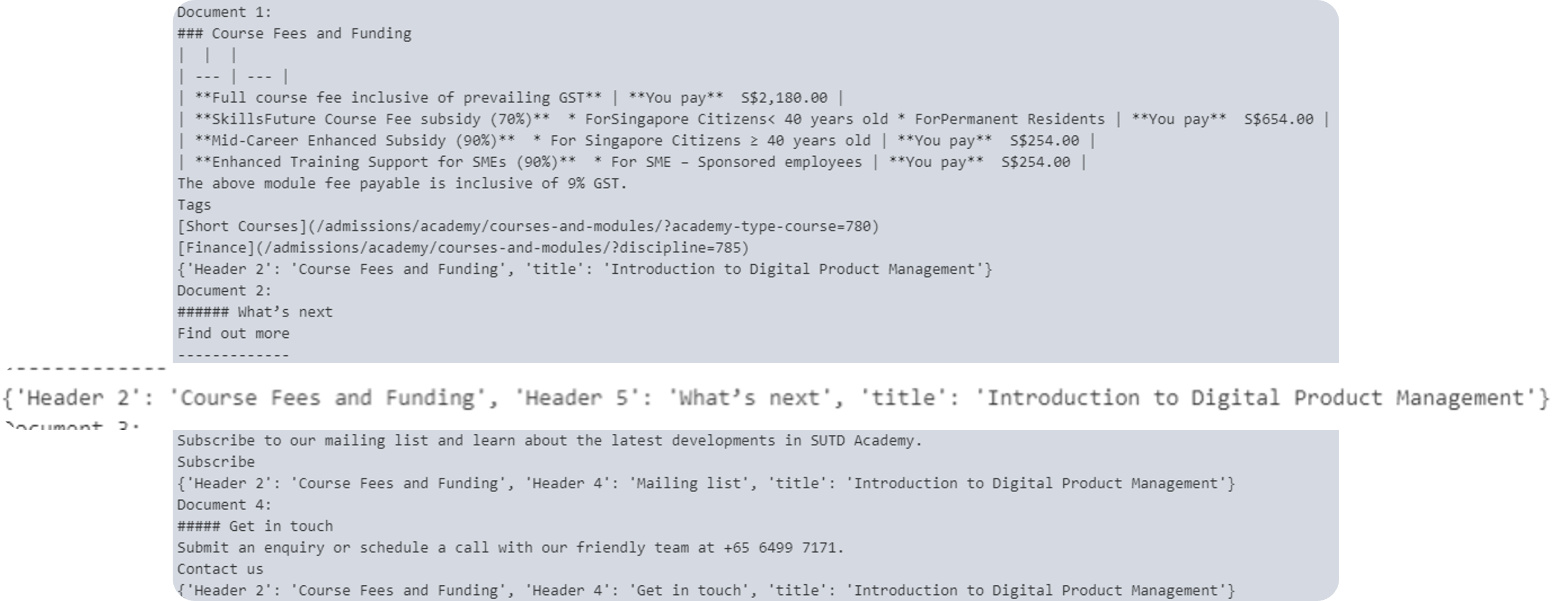
We then chunked the data using header-based chunking so that it will work better. We also made sure to add any necessary metadata such as the title of the page and respective headers so that the chunks will have more context.
Finally, we used sentence-transformers/all-mpnet-base-v2 as our embedding model and FAISS as our vector store. These were chosen as they are fast and efficient and good enough for our use case.
Retrieval Augmented Generation (RAG)
We then built our first RAG system using Llama 3.2 3B-Instruct and compared it with the non-RAG base model.
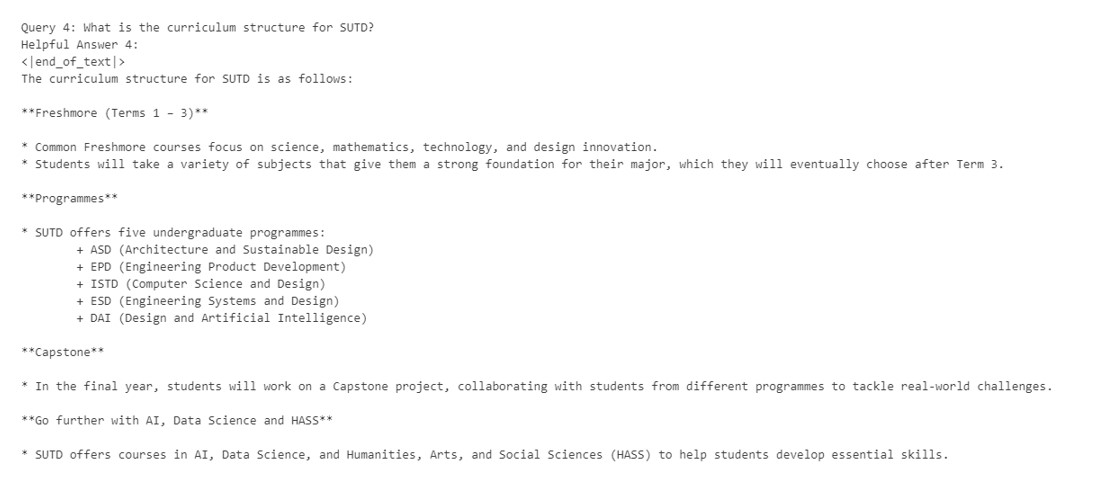
We can see that the RAG system is able to retrieve relevant information from the knowledge base and answer the questions to a good degree.
For comparison, this is an answer from the non-RAG model:

We can see that it cannot even identify SUTD as a university and is confusing it with another university in Singapore called NTU.
Finetuning
Now that we have a working RAG system, we wanted to further improve the performance of the chatbot by finetuning it with context of SUTD and also tested to see if a smaller finetuned model will be able to perform well.
We used the Llama 3.2 1B and first finetuned it on the Alpaca dataset so that it can learn instructed tasks. We then finetuned it again on a question and answer dataset. For this, we finetuned about 9% of the model parameters using unsloth.
My friends then generated a synthetic dataset of questions and answers pair using Gemini 2.0 API with web search using Tavily.
The generated dataset can be found on my friend`s hugging face dataset here: Keith’s QA Dataset
Finally, we finetuned our model and the models can be found here on my hugging face: Our Finetuned Model.
Evaluation
To evaluate the performance of our model, we first manually evaluated based on Accuracy of Answer, Relevance of Retrieved Context and Groundedness of the Answer.
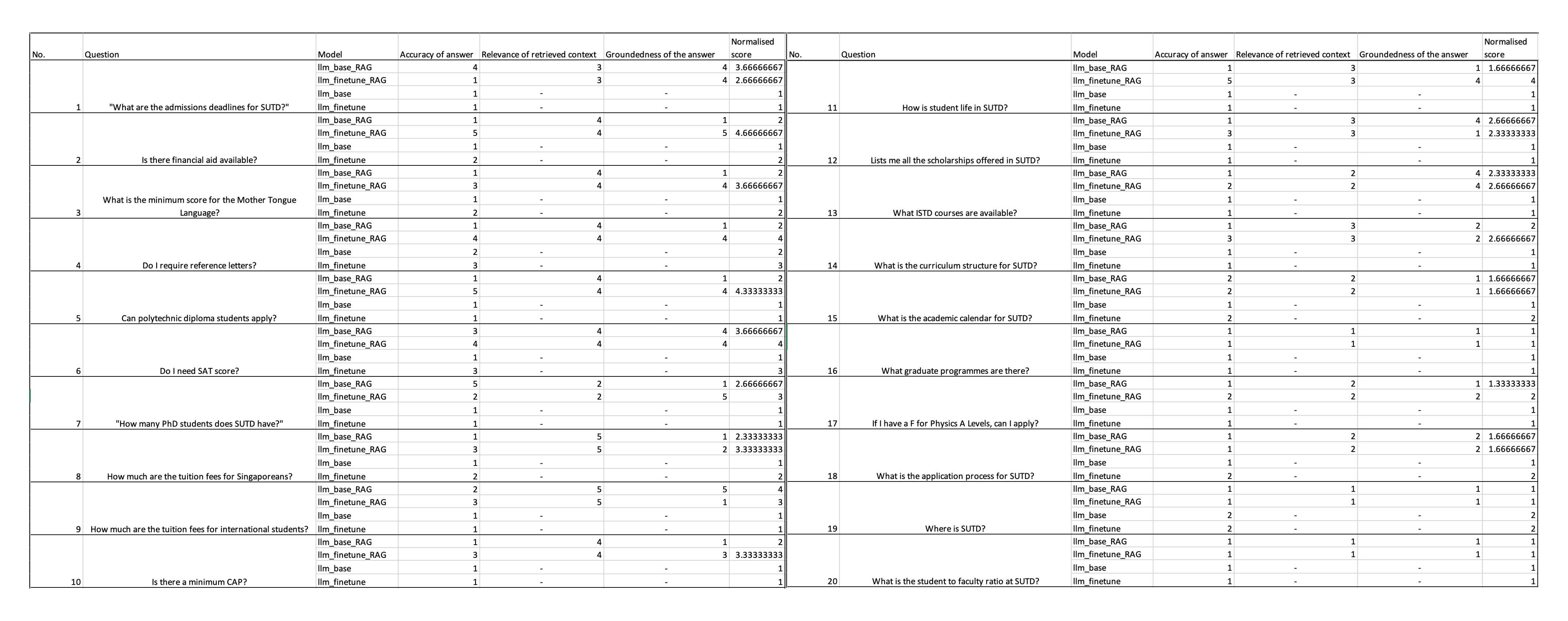
We found that the finetuned RAG model overall performed better than the fintuned non-RAG model and base RAG model which is what we wanted!
Bonus: LLM as a Judge
As an added bonus, we decided to also evaluate the performance of our model using LLM as a judge. I wrote up a simple prompt and asked Gemini 2.0 to evaluate the performance of our model based on the same criteria as above.

In 15/20 questions, the LLM agreed that the finetuned RAG model performed better than the finetuned non-RAG model and base RAG model and provided good reasoning for it. This further confirms our manual evaluation was correct and that we have succeeded in our task!
Conclusion
This was an interesting exercise and I got to better understand the behaviours of smaller LLM models and how they can be improved using methods such as finetuning and RAG. I also learnt a lot about the importance of chunking and embeddings in building a good RAG system.